
 网址导航
网址导航 七哩小店
七哩小店 七哩圈子
七哩圈子 问答
问答 手机软件
手机软件 电脑软件
电脑软件 源码仓库
源码仓库 固件仓库
固件仓库 游戏源码
游戏源码 技术教程
技术教程

今日头条是一个非常火的自媒体平台,你有没有发现你在今日头条永远可以刷到感兴趣的内容,这是为什么呢?这要归功于今日头条后面强大的算法系统。今日头条资深算法架构师曹欢欢博士,为了消除外界对今日头条算法的误解,于是公开了今日头条的算法原理,文章末尾通过视频方式的方式为大家科普今日头条算法原理,供大家参考学习。(文章末尾附高清视频)

今日头条算法原理
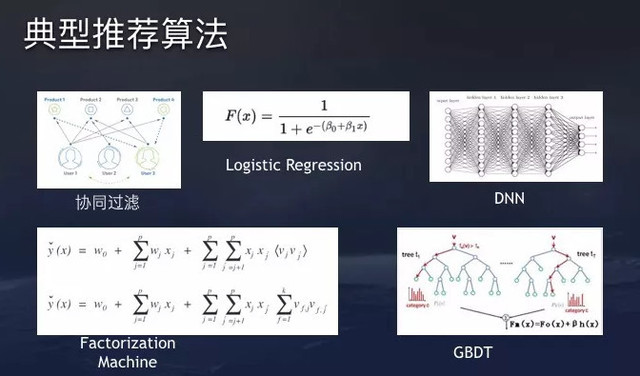
1、典型推荐算法
今日头条内容推荐系统,实际上就是设计一个用户对内容满意度的函数,这个函数需要设计三个维度的变理:
第一个维度是内容,头条内容包括图文、视频、UGC小视频、问答、微头等不同类的内容,不同类型的内容都有着自己特征,系统需要考虑的是如何提取不同内容类型的特征向用户做好推荐;
第二个维度是用户特征,包括用户兴趣标签、职业、年龄、性别等,还要挖掘用户隐藏兴趣等;、
第三方维度就是环境特征,这也是移动互联网的特征,用户会随时随地移动,场景包括公司、通勤、旅游等,不同的场景,用户偏好也会有所不同;
根据以上三个维度,系统会给出一个预估,即预估在此场景推荐此内容给用户是否合适。
大规模推荐模型在线训练,越用越准。

2、大规模推荐模型在线训练算法
头条大规模推荐模型在线实时训练,这套算法对于信息流产品是非常重要的,用户行业信息被系统捕捉并反馈至下一刷推荐内容。
头条线上目前基于storm集群实时处理样本数据,包括点击、展现、收藏、分享等动作类型,模型参数服务器是内部开发的一套高性能的系统,因为头条数据规模增长太快,类似的开源系统稳定性和性能无法满足,而我们自研的系统底层做了很多针对性的优化,提供了完善运维工具,更适配现有的业务场景。
目前,头条的推荐算法模型在世界范围内也是比较大的,包含几百亿原始特征和数十亿向量特征。整体的训练过程是线上服务器记录实时特征,导入到Kafka文件队列中,然后进一步导入Storm集群消费Kafka数据,客户端回传推荐的label构造训练样本,随后根据最新样本进行在线训练更新模型参数,最终线上模型得到更新。这个过程中主要的延迟在用户的动作反馈延时,因为文章推荐后用户不一定马上看,不考虑这部分时间,整个系统是几乎实时的。

3、召回策略设计算法
由于头条要处理的数据太大了,加上头S条小视频内容,要处理的内容有千万级别,内容推荐不可能全部由模型预估,所以就需要设计召回策略,每次向用户推荐的内容都是从海量内容中筛选出来的,召回策略重要的设计是性能处理要求是极致,一般超时不能超过50毫秒。
3分钟了解今日头条算法原理(科普版)官方视频供大家参考。
